- 1 教師なし学習
- 2 特異値分解 (SVD)
- 3 多次元尺度構成法
- 4 t-SNE
- 5 次元削減
- 6 k-means法(階層なしクラスタリング)
- 7 ウォード法(階層ありクラスタリング)
- 8 主成分分析(Principal ComponentAnalysis、PCA)
- 9 協調フィルタリング(collaborative filtering)
- 10 コールドスタート問題
- 11 コンテンツベースフィルタリング
- 12 トピックモデル
- 13 潜在的ディリクレ配分法(LDA:Latent Dirichlet Allocation)
- 14 LSI(Latent Semantic Indexing)
- 15 k近傍法(knn法:k nearest neighbor)
- 16 ユークリッド距離(Euclidean distance)
- 17 マハラノビス距離
教師なし学習

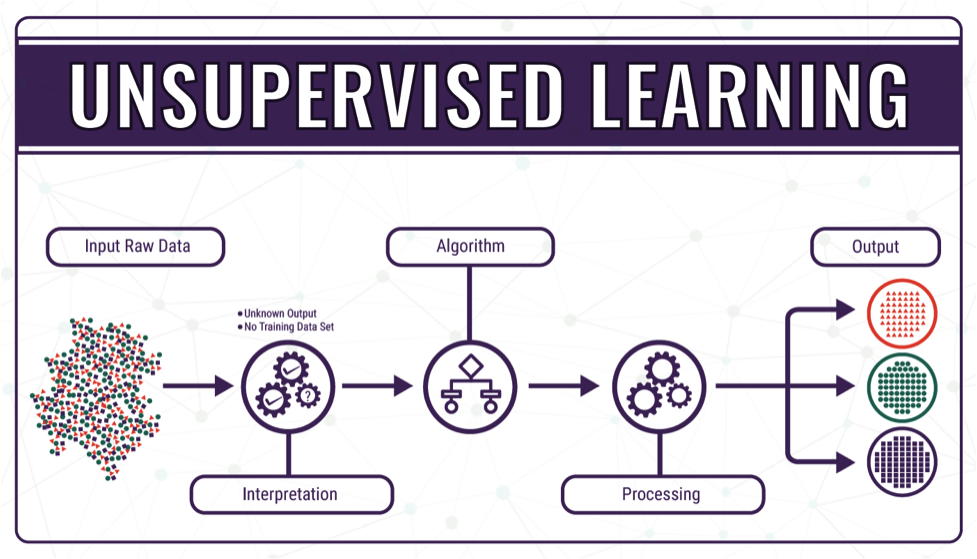
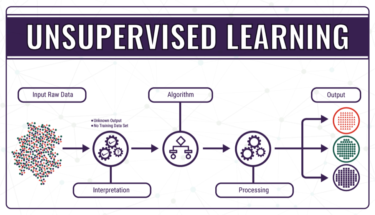
教師なし学習は、学習データに正解を与えない状態で学習させる学習手法です。学習データに正解を与える「教師あり学習」と対をなす機械学習の学習手法となっています。教師なし学習では予測や判定の対象となる正解が存在しないため、教師あり学習とは違い回帰や分類の問題には対応できません。回帰は株価の予測や気象分析に利用されるアルゴリズムであり、分類は植物や動物などのカテゴライズを実現するアルゴリズムです。
教師なし学習で行なう代表的な例は「クラスタリング」と「次元削減」です。クラスタリングはデータの特徴からグルーピングすることであり、例えばA・B・Cという特徴を持つデータが無造作に配置されていた場合、人間であれば正解を示さずともAグループ・Bグループ・Cグループとグルーピングできます。教師なし学習のクラスタリングを用いることで、コンピュータが自動的にグルーピングすることが可能となります。
教師なし学習を利用する目的は、データ内に存在する未知のパターンを見つけ出すことにあります。
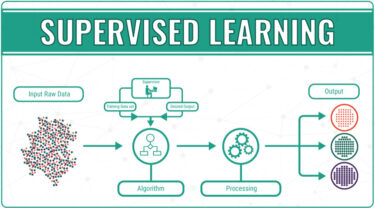
教師あり学習 教師あり学習は、与えられたデータ(入力)を元に、そのデータがどんなパターン(出力)になるのかを識別・予測すること。 例えば、下記のような例がある。 過去の売上から、将来の売上を予測したい 与えられた動物の[…]
特異値分解 (SVD)
特異値分解(singular value decomposition: SVD)とは線形代数学における複素数あるいは実数を成分とする行列に対する行列分解の一手法であり、Autonneによって導入された。悪条件方程式の数値解法で重宝するほか、信号処理や統計学の分野で用いられる。特異値分解は、行列に対するスペクトル定理の一般化とも考えられ、正方行列に限らず任意の形の行列を分解できる。
多次元尺度構成法
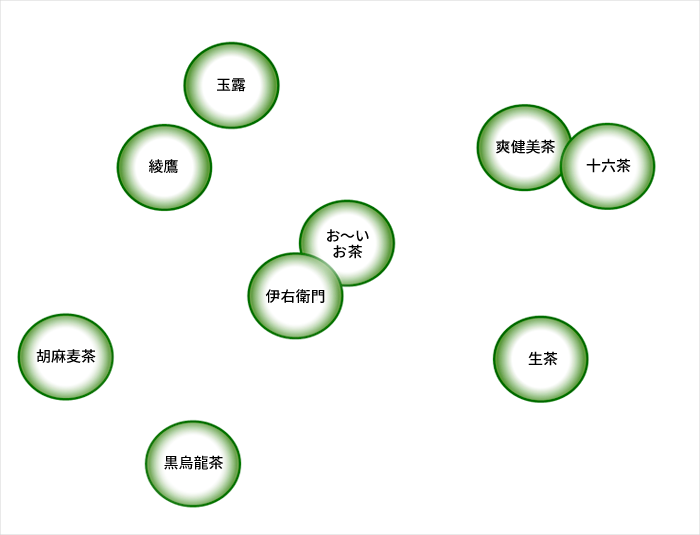
多次元尺度構成法(Multi-dimensional scaling)とは、類似度を元に対象の関係を視覚的に分かりやすい形に変換する分析手法です。 主成分分析の様に分類対象物の関係を低次元空間における点の布置で表現し、古典的MDSは主座標分析 とも呼ばれ、さらに主座標分析において距離にユークリッド距離を用いた場合は主成分分析と等価になります。
分析された結果はポジショニングマップなどのグラフとして活用します。
たとえば、ペットボトルのお茶のブランドに関して、消費者がどのように認知しているかを市場調査でデータを集めて、以下のようなプロダクト・マップを作成することができます。
機械翻訳 機械翻訳(きかいほんやく、英: machine translation)とは、ある自然言語を別の自然言語に翻訳する変換を、コンピュータを利用して全て(ないし、可能な限り全て)自動的に行おうとするもの[…]

t-SNE
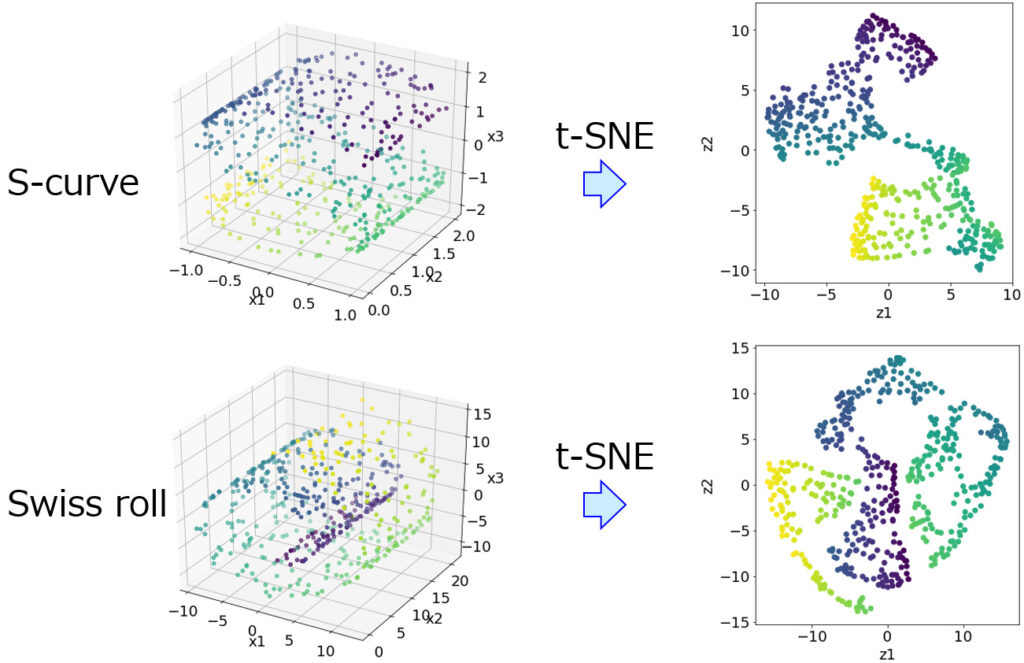
t分布型確率的近傍埋め込み法
(T-distributed Stochastic Neighbor Embedding, t-SNE)は、Laurens van der Maatenとジェフリー・ヒントンにより開発された可視化のための機械学習アルゴリズムです。
高次元データを2次元や3次元に落とし込むための最適な非線形次元削減手法であり、具体的には、高次元のデータ集合を2次元または3次元へ配置する際に、高い確率で類似した集合が近傍に、異なる集合が遠方となるように対応付けます。
次元削減
次元削減(Dimensionality reduction、dimension reduction)とは、高次元空間から低次元空間へデータを変換しながら、低次元表現が元データの何らかの意味ある特性を保持することである。
データの増加と機械学習 機械学習:人工知能のプログラム自身が学習する仕組み。 コンピュータは与えられたサンプルデータを通してデータに潜むパターンを学習。 ユーザーの好みを推測するレコメンデーションエンジンや迷惑メールを検[…]
k-means法(階層なしクラスタリング)
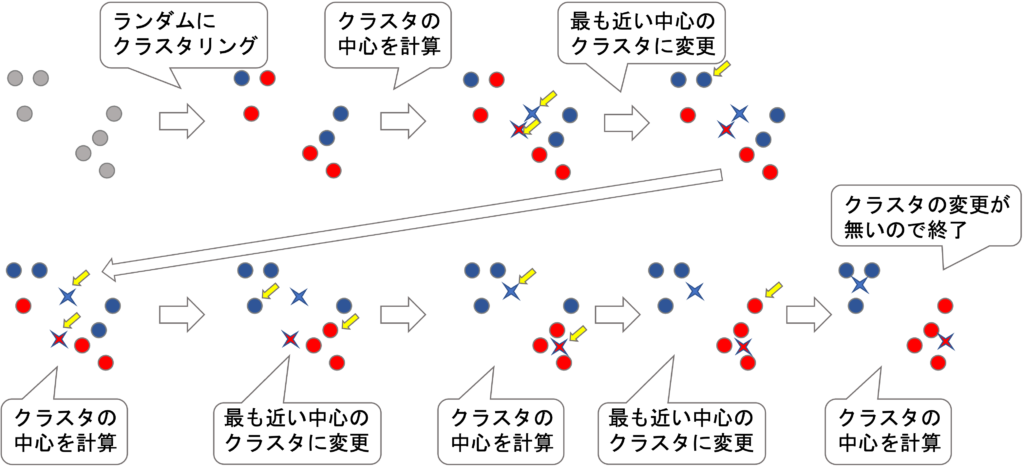
k平均クラスタリングはデータのグルーピングを行う手法であり、その名前の「k」というのはデータをグループ分けした結果、何グループにまとめられるのかを表しています。
つまりk個のグループに分ける手法ということで「k」平均クラスタリングという名前が付けられています。この「k」の具体的な数値の決定は分析者に委ねられています。
データを分けるグループ数を2個にするか3個にするか4個、5個…にするかは分析者がはじめに自由に決定できます。またk平均クラスタリングの「平均」という言葉は、k個のグループの各重心を「平均」により導くことに由来しています。
k平均クラスタリングでは各データをk個のグループのうち最も距離が近いグループに割り振ります。
ウォード法(階層ありクラスタリング)
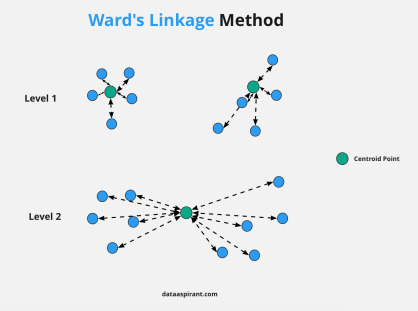
ウォード法は、それぞれのデータの平方和(それぞれのデータと平均値の差を二乗した値の和)を求め、平方和が小さなものからクラスタを作っていきます。 平方和はデータのばらつきを表すもので、平方和が大きいほどデータのばらつきが大きい、逆に平方和が小さいほどデータのばらつきは小さいということになります。クラスタリングのまとまりを表した樹形図のことをデンドログラム(dendrogram)といいます。
最初に、すべてのデータの組み合わせに対して平方和を求めます。そのなかで、平方和が一番小さくなる組み合わせのものが最初のクラスタです。そして、そのクラスタを含めた各組合せに対して再度平方和を求めてクラスタ作成を繰り返します。
人工無脳(知識なしでも知性があるように感じる人間心理の不思議) 人工無脳:チャットボット、おしゃべりボットなどと呼ばれているコンピュータプログラム。特定のルール・手順に沿って会話を機械的に処理するだけで、実際は会話の内容を理解して[…]

主成分分析(Principal ComponentAnalysis、PCA)
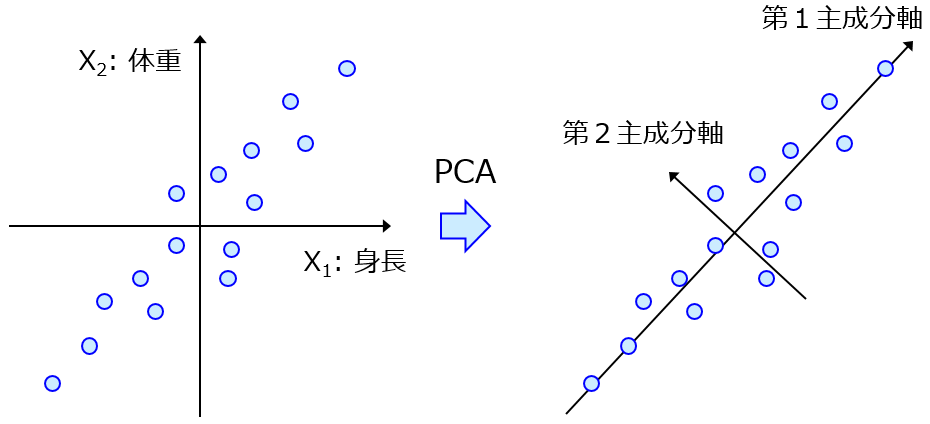
データの特徴量間の関係性、相関を分析しデータの構造をつかむ手法。特に特徴量の数が多い場合に用いられ、相関をもつ多数の特徴量から相関のない少数の特徴量へと次元削減することが主たる目的。ここで得られる少数の特徴量を主成分という。 線形な次元削減であり、計算量の削減ができ次元の呪いの回避が可能となる。寄与率を調べれば各成分の重要度が把握でき、主成分を調べれば各成分の意味を推測しデータの可視化が可能となる。
主成分分析以外には、特異値分解(Singular Value Decomposition、SVD)、多次元尺度構成法(Multi-Dimensional Scaling、MDS)がよく用いられる。可視化によく用いられる次元圧縮の手法は、t-SNE(t-distributed Stochastic NeighborEmbedding)がある。t-SNEのtはt分布のtである。
全人類をデジタル管理 国際的な資本家(グローバリスト)がワクチンを推し進める理由はお金だけではありません。 今、国連は、SDGs(持続可能な開発目標)の「2030年までにすべての人に出生証明を含む法的なアイデン[…]


協調フィルタリング(collaborative filtering)
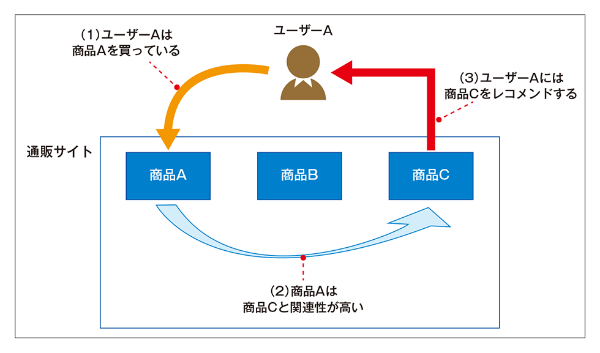
レコメンデーション(recommendation)に用いられる手法のひとつであり、レコメンドシステム(推薦システム)に用いられる。ECサイトで表示される「この商品を買った人はこんな商品も買っています」の裏側には協調フィルタリングが用いられている。協調フィルタリングは事前にある程度の参考となるデータがないと推薦を行うことができない(コールドスタート問題(cold startproblem))
コールドスタート問題
コールドスタート問題(cold startproblem)とは、レコメンデーションにおいて、サイトの新規ユーザーやサイトに新しく登録された商品の情報の場合に、ユーザーの好みを判断する情報が乏しいため適切な情報を推薦することができないことです。
また、商品の入れ替わりが早いファストファッション系のECサイトでは、類似度を判断するのに十分なデータがたまる頃には新し商品が出てしまうためたまったデータが意味を持たなくなってしまうことがあります。
全人類をデジタル管理 国際的な資本家(グローバリスト)がワクチンを推し進める理由はお金だけではありません。 今、国連は、SDGs(持続可能な開発目標)の「2030年までにすべての人に出生証明を含む法的なアイデン[…]
コンテンツベースフィルタリング

ユーザーではなく商品側に何かしらの特徴量を付与し、特徴が似ている商品を推薦する方法をコンテンツベースフィルタリング(content-based filtering)という。対象ユーザーのデータさえあれば推薦を行うことができるのでコールドスタート問題を回避することができるが、反対に他のユーザー情報を参照することができない。
アイテムにはあらかじめ特徴的なキーワードを割り当てておく.ユーザの行動やアイテムの閲覧履歴等を参考にアイテムに記されているキーワード等からユーザの嗜好の特徴量を構築していく。
まず大前提として「陽性者」と「感染者」は違います。 メディアによって「陽性者」と「感染者」が混同されて使用されていますが、「陽性者」の中には無症状の方も大勢います。この方々は厳密に言うと「感染者」ではありません。ニュース等で「新規感[…]

トピックモデル
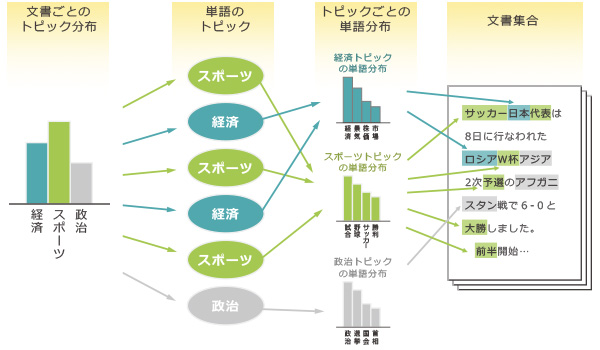
トピックモデルとは、文書が複数の潜在的なトピックから確率的に生成されると仮定したモデルです。k-means法やウォード法と同様クラスタリングを行います。 また、文書内の各単語はあるトピックが持つ確率分布に従って出現すると仮定します。 トピックモデルでは、トピックごとに単語の出現頻度分布を想定することで、トピック間の類似性やその意味を解析できます。
文章を潜在的な「トピック(単語の出現頻度分布)」から確率的に現れるのものと仮定して分析を行う。各トピックの確率分布を推定できれば、傾向や単語の頻度、次にくる文章の予測が可能となる。各文書データ間の類似度を求めることができるため、レコメンドシステム(推薦システム)に用いることができる。
トピックモデルの代表的な手法に潜在的ディリクレ配分法(latent Dirichlet allocation、LDA)があります。
潜在的ディリクレ配分法(LDA:Latent Dirichlet Allocation)
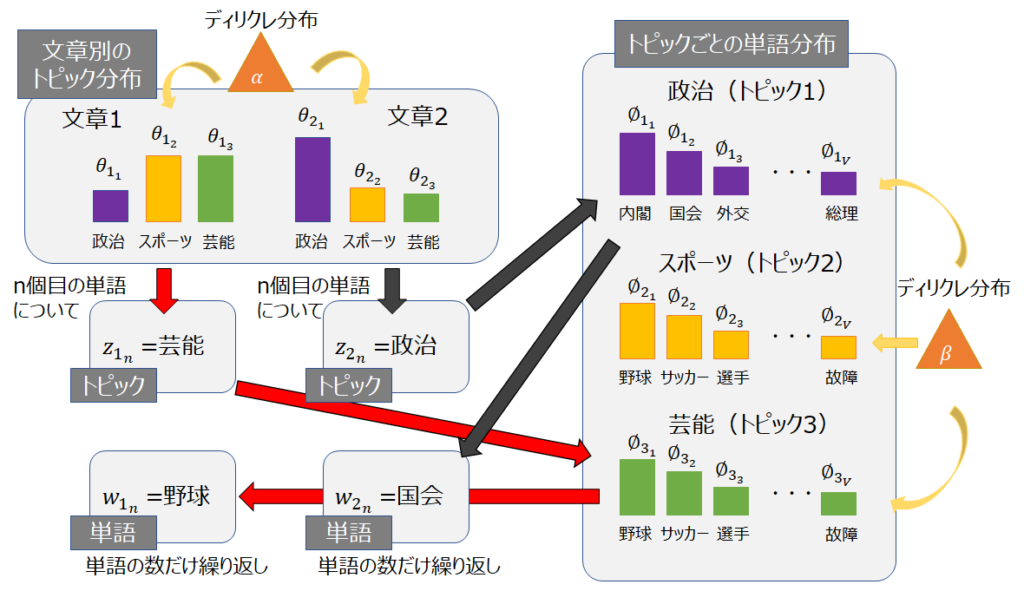
潜在的ディリクレ配分法:LDA(Latent Dirichlet Allocation)とは,一つの文書に 対して複数のトピックが存在すると想定した確率的トピックモ デルであり,それぞれのトピックがある確率を持って文書上に 生起するという考えの下,そのトピックの確率分布を導き出す手法である。
文中の単語から、トピックを推定する教師なし機械学習の手法。ディレクトリ分布という確率分布を用いて、各単語から隠れたあるトピックから生成されているものとしてそのトピックを推定する。
LSI(Latent Semantic Indexing)
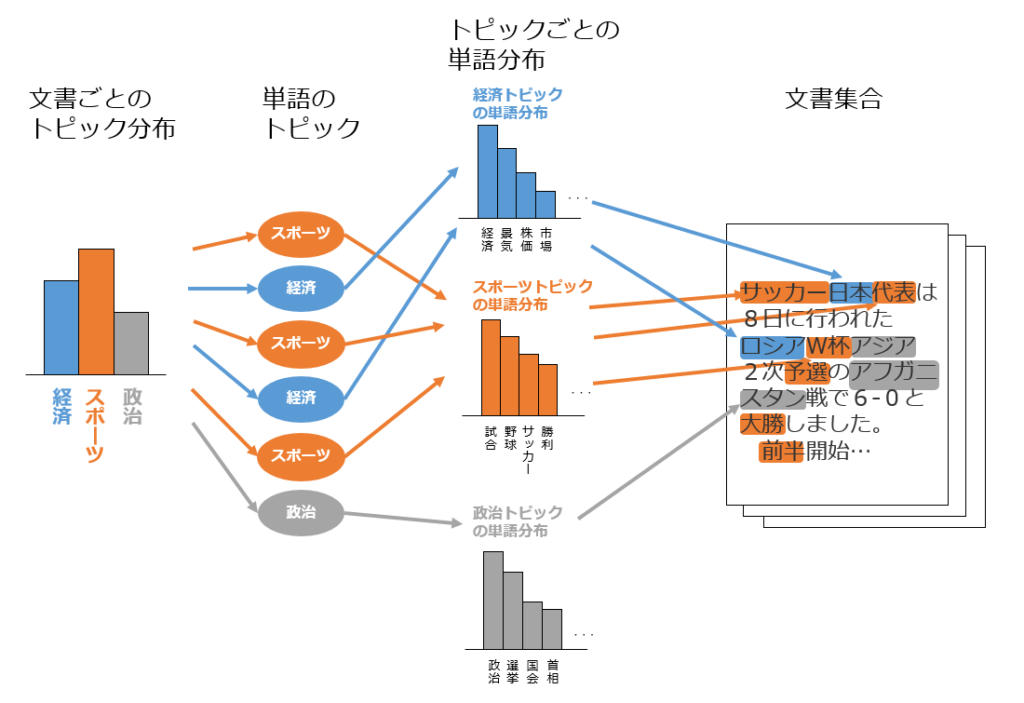
潜在的意味解析と呼ばれるトピックモデルの1種。文章ベクトルにおいて複数の文章に共通に現れる単語を解析することによって、低次元の次元の潜在意味空間を構成する方法。ある行列を複数の行列の積で表現する行列分解の一つである特異値分解が用いられれる。文章中の情報を圧縮することができ、これによりトピックを推定することができる。
k近傍法(knn法:k nearest neighbor)
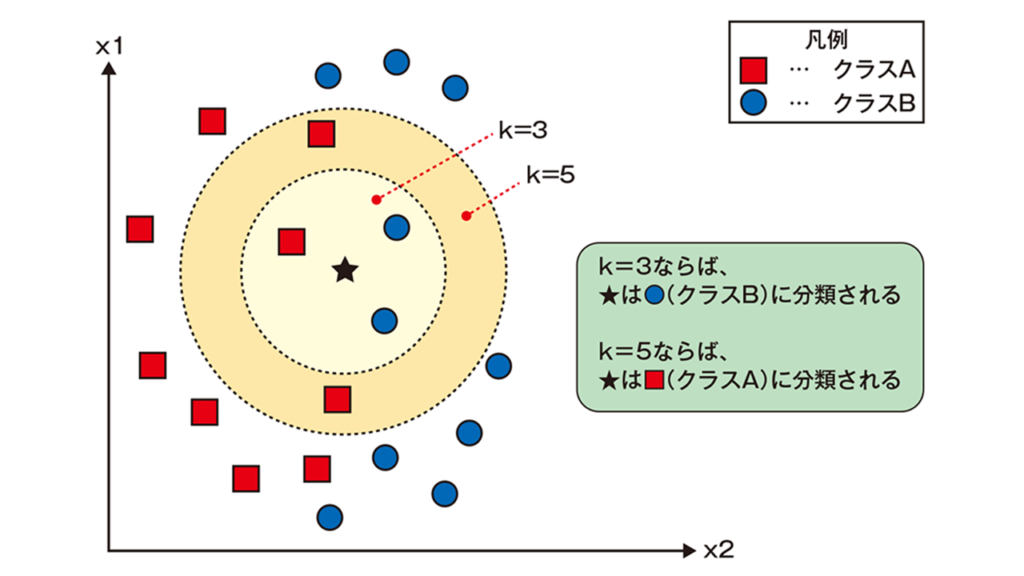
k近傍法とは、分類に使われる手法の一つで、与えられた学習データをベクトル空間上にプロットしておき、未知のデータが得られたら、そこから距離が近い順に任意のk個を取得し、その多数決でデータが属するクラスを推定する。独立変数が2個しかない場合は、2次元上にデータをプロットできるので、より直感的に理解できる。
クラスのサンプル数に偏りに弱いという欠点がある。各クラスのデータ数の偏りが少なく、各クラスがはっきりと分かれている場合には有効である。アルゴリズムは単純であるが、訓練データが多いと計算に時間がかかる。
ユークリッド距離(Euclidean distance)
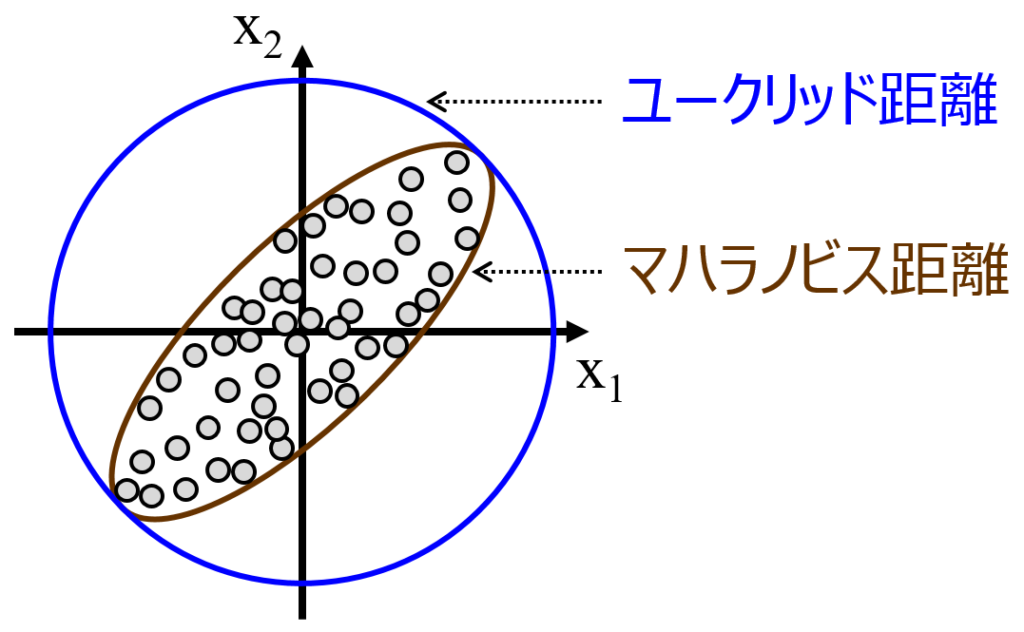
ユークリッド距離とは、2点間の直線距離のことである。 人が定規で測るような2点間の通常の距離であり、ピタゴラスの公式によって与えられる。 マーケティングリサーチでは、クラスター分析の際などに用いられることが多い。 ユークリッド距離に対して、各次元ごとに標準偏差で割り、値の分散を標準化した上でのユークリッド距離を標準ユークリッド距離と呼ぶ。
マハラノビス距離
マハラノビス距離とは、多変数間の相関関係を取り入れて、既知のサンプルとの関係を明らかにする距離です。既知のサンプルとの関係は、例えば品質管理において良品のデータの分布を持っている場合、それを基準に異常検知に使える基準が作れることを意味します。標本点と分布の間の尺度であり、ベクトルyから平均μ及び共分散Σを持つ分布の場合、標準偏差単位でyが平均からどの程度離れているかを表す。