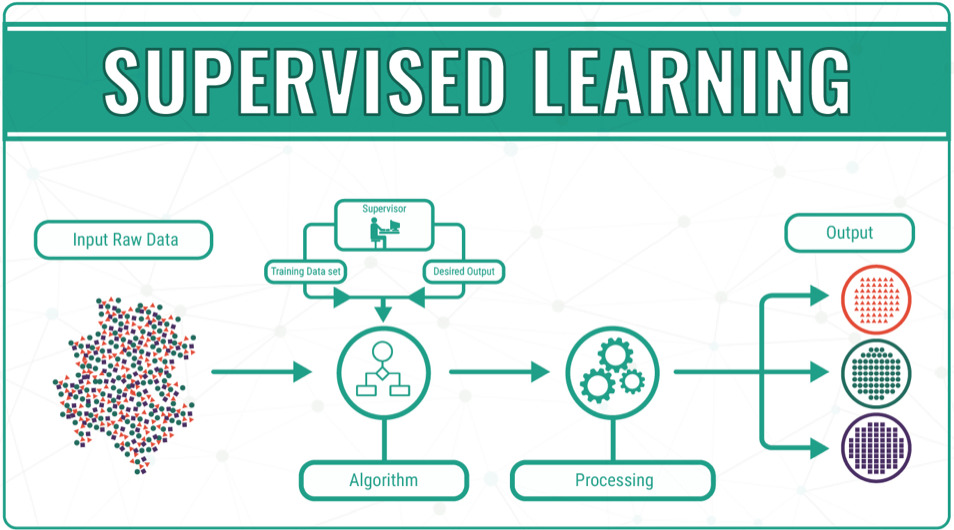
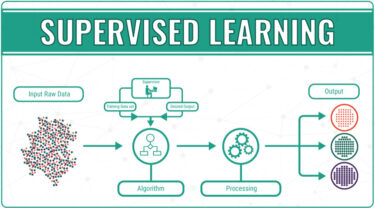
教師あり学習
教師あり学習は、与えられたデータ(入力)を元に、そのデータがどんなパターン(出力)になるのかを識別・予測すること。
例えば、下記のような例がある。
- 過去の売上から、将来の売上を予測したい
- 与えられた動物の画像が、何の動物かを識別したい
半教師あり学習
半教師あり学習は、トレーニング中に少量のラベル付きデータと大量のラベルなしデータを組み合わせる機械学習へのアプローチです。半教師あり学習は、教師なし学習と教師あり学習の間にあります。それは弱い監督の特別な例です。 ラベルなしデータを少量のラベル付きデータと組み合わせて使用??すると、学習精度が大幅に向上します。
どう組み合わせるかには、幾つかの手法がある。
代表的な手法としては、「教師なし学習で特徴表現を獲得した後で、教師ありでそのモデルを再学習する方法」がある。このようなステップを踏むことで、少ない教師データしかなくても、通常の教師あり学習よりも精度を高められると一般的にいわれている。
分類問題、回帰問題
教師あり学習の問題は出力値の種類によって、大きく2種類(回帰と分類問題)に分けられる。売上を予測したい場合は数字(連続する値)が出力値となり、動物の画像を予測したい場合はカテゴリー(連続しない値)が出力値となります。前者のように連続値を予測する問題のことを「回帰問題」といい、後者のように離散値を予測する問題のことを「分類問題」といいます
本コンテンツは、日本ディープラーニング協会のG検定を想定したコンテンツとなっております。 人工知能の定義 人工知能とは何か 「人工知能(Artificial Intelligence)」:1956年にアメリカで開催され[…]

線形回帰(LinearRegression)
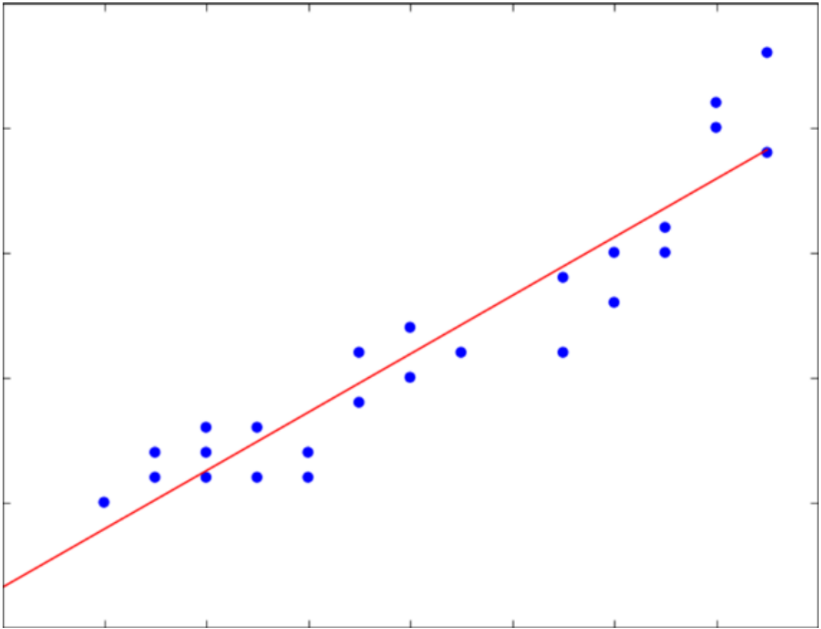
回帰問題に用いる手法でシンプルなモデルの1つデータ(の分布)があったときに、そのデータに最も当てはまる直線を考える。線形回帰に正則化項を加えた手法として以下の方法がある。
| ラッソ回帰 | リッジ回帰 |
| L1正則化 | L2正則化 |
| マンハッタン距離を用いる | ユークリッド距離を用いる |
| 一部パラメータの値を0とすることで特徴選択が可能 | パラメータの大きさに応じて0に近づけることで、汎化されたモデルを取得する |
両方を組み合わせた手法を Elastic Net という。
ロジスティック回帰
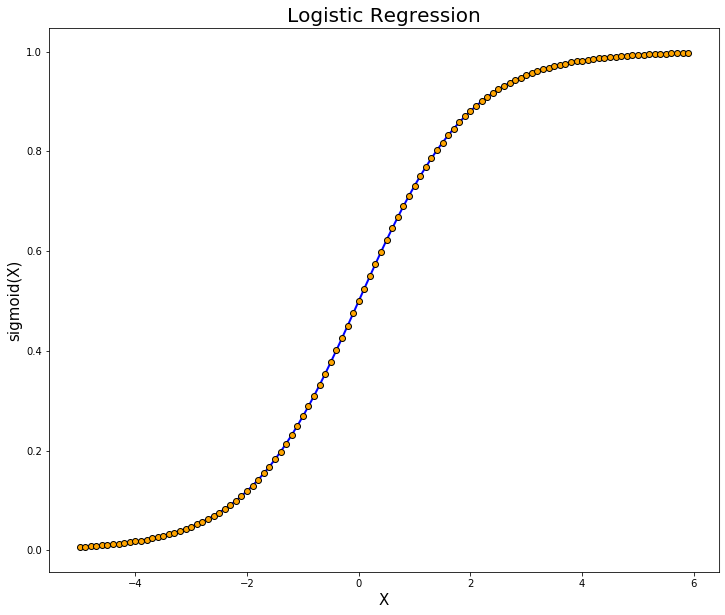
線形回帰を分類問題に応用したアルゴリズム。対数オッズを重回帰分析により予測して、ロジスティック(シグモイド)関数で変換することで出力の正規化によって予測値を求めることで、最大確率を実現するクラスをデータが属するクラスと判定する。目的関数は尤度関数を用いる。ロジット変換を行うことで、出力値が正規化される。3種類以上の分類は、ソフトマックス関数を使う。
決定木
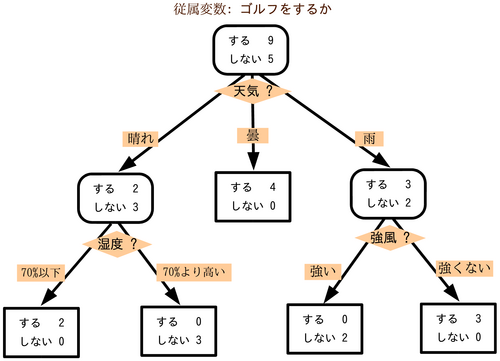
分類木と回帰木を組み合わせたものでツリー(樹形図)によって条件分岐を繰り返すことで境界線を形成してデータを分析する手法。決定木は一般に仕組みがわかりやすいだけでなく、データのスケールを事前に揃えておく必要がなく、分析結果の説明が容易である特徴がある。
訓練データを用いて決定木を過学習させたあと、検証データを用いて性能低下に寄与している分岐を切り取ることを剪定という。これにより過学習を抑制できる。
条件分岐を繰り返す際に条件分岐の良さを判断するための基準をあらかじめ定めておく。分類問題においては情報利得の最大化を判断基準とする。

ランダムフォレスト
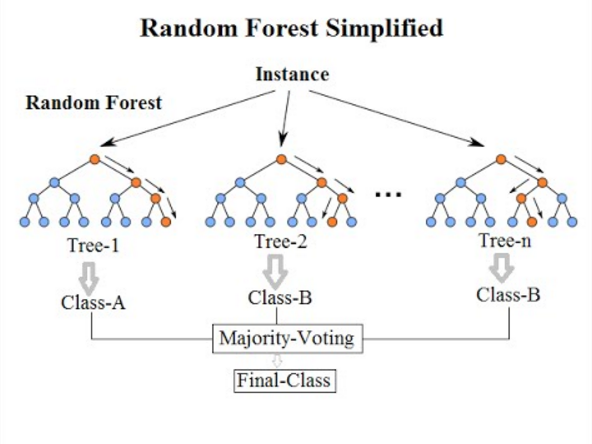
「決定木」において特徴量をランダムに選びだす手法。ランダムフォレストでは特徴量をランダムに選び出す(ランダムに複数の決定木を作る)。学習に用いるデータも全データを使うのではなく、それぞれの決定木に対してランダムに一部のデータを取り出して学習を行う(ブートストラップサンプリング)。複数の決定木の結果から、多数決で出力を決定することで全体的に精度向上することを期待している。
人工無脳(知識なしでも知性があるように感じる人間心理の不思議) 人工無脳:チャットボット、おしゃべりボットなどと呼ばれているコンピュータプログラム。特定のルール・手順に沿って会話を機械的に処理するだけで、実際は会話の内容を理解して[…]

バギング
複数のモデルで 学習することをアンサンブル学習、全体から一部のデータを用いてアンサンブル学習する方法をバギングという。ランダムフォレストはバギングの中で決定木を用いている手法という位置付けになる。
精度:低、学習時間:短
ブースティング
ブースティングは、予測データ分析のエラーを減らすために機械学習で使用される方法です。バギングと同様に一部データを繰り返し抽出して、複数モデルを学習させるアプローチをとります。バギングとの違いは、複数のモデルを一気に並列に作成するか(バギング)、逐次的に作成するか(ブースティング)になります。
ブースティングでは、まず1つのモデルを作成し、学習します。次に作成するモデルでは、そこで誤認識してしまったデータを優先的に正しく分類できるように学習します。こうして順次、前のモデルで誤ったデータに重みを付けて学習を進めていき、最終的に1つのモデルとして出力を行います。
データサイエンティストは、機械学習モデルと呼ばれる機械学習ソフトウェアをラベル付きデータでトレーニングして、ラベルなしデータについて推測します。1 つの機械学習モデルでは、トレーニングデータセットの精度によっては予測エラーが発生する可能性があります。
例えば、猫を識別するモデルが白猫の画像のみでトレーニングされている場合、黒猫を誤認することがあります。ブースティングは、システム全体の精度を向上させるために複数のモデルを順番にトレーニングすることで、この問題を克服しようとします。
ブースティングには、AdaBoost、XGBoost、勾配ブースティングなどがある。
精度:高 、学習時間:長
AdaBoost(アダプティブブースティング)
AdaBoost(Adaptive Boosting)は、Yoav Freund と Robert Schapire によって考案された機械学習アルゴリズムです。メタアルゴリズムであり、他の多くの学習アルゴリズムと組み合わせて利用することで、そのパフォーマンスを改善することができます。
最も初期に開発されたブースティングモデルの 1 つです。ブースティングプロセスのすべての反復で適応し、自己修正を試みます。
AdaBoost は、最初は各データセットに同じ重みを与えます。次に、すべての決定木の後にデータポイントの重みを自動的に調整します。次のラウンドで修正できるようにするために、誤って分類されたアイテムにより多くの重みを与えます。残留誤差、または実際の値と予測値の差が許容可能なしきい値を下回るまで、このプロセスを繰り返します。
AdaBoost は多くの予測子で使用でき、通常、他のブースティングアルゴリズムほど感度が高くありません。このアプローチは、特徴間に相関関係がある場合やデータの次元が高い場合にはうまく機能しません。全体として、AdaBoost は分類問題に適したタイプのブースティングです。
勾配ブースティング
勾配ブースティング (GB) も、シーケンシャルトレーニング手法であるという点で AdaBoost に似ています。AdaBoost と GB の違いは、GB が誤って分類されたアイテムにより大きな重みを与えないことです。代わりに、GB ソフトウェアは、現在の基本学習器が常に前の基本学習器よりも効果的であるように、基本学習器を順次生成することによって損失関数を最適化します。この手法は、AdaBoost のようにプロセス全体でエラーを修正するのではなく、最初に正確な結果を生成しようとします。このため、GB ソフトウェアはより正確な結果をもたらす可能性があります。勾配ブースティングは、分類と回帰ベースの問題の両方に役立ちます。
極端な勾配ブースティング(XGBoost)
極端な勾配ブースティング (XGBoost) は、複数の方法でコンピューティング速度とスケールインの勾配ブースティングを改善します。XGBoost は CPU で複数のコアを使用するため、トレーニング中に学習を並行して行うことができます。これは、広範なデータセットを処理できるブースティングアルゴリズムであり、ビッグデータアプリケーションにとって魅力的です。XGBoost の主な機能は、並列化、分散コンピューティング、キャッシュの最適化、およびアウトオブコア処理です。
サポートベクターマシン(SVM)
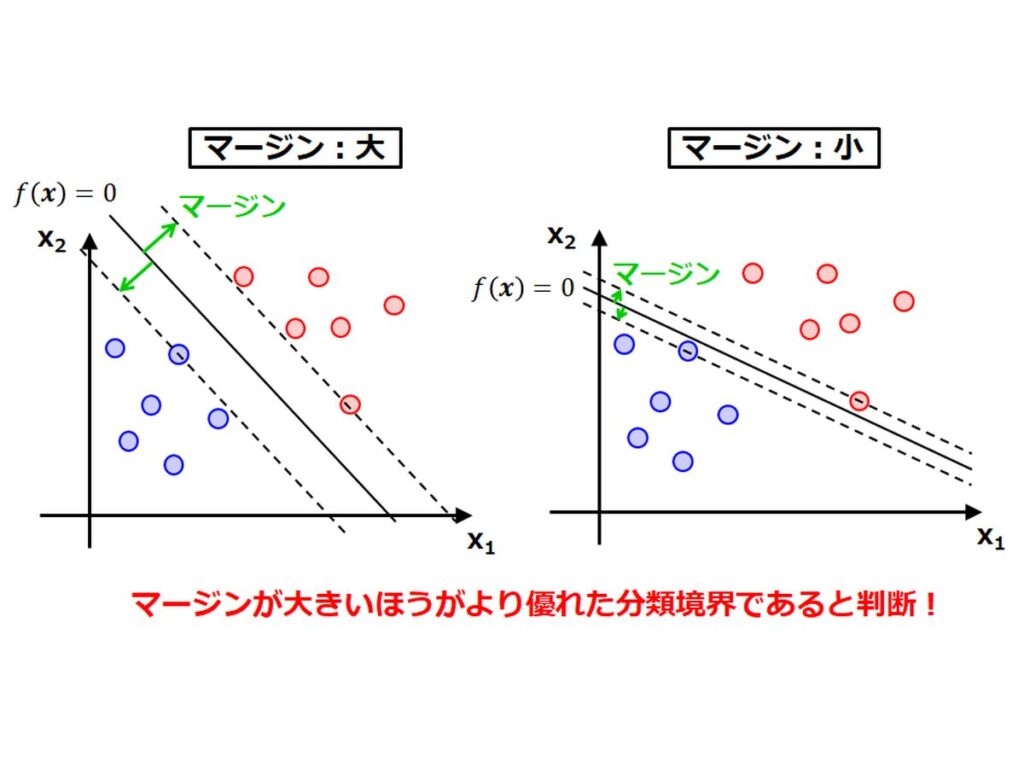
サポートベクターマシン(Support Vector Machine)は、SVMとも呼ばれる。各データ点(サポートベクトル)との距離(マージン)が最大となるような境界線を求めることで、パターン分類を行う。この距離を最大化することをマージン最大化と言う。スラック変数を用いることで、どの程度誤分類を許容するか調整できるようになり、誤分類されたデータに寛容になる。
SVMではデータをあえて高次元に写像することで、その写像後の空間で線形分類できるようにするカーネル法というアプローチがとられた。この写像に用いられる関数のことをカーネル関数と言う。計算量が非常に大きくなるため、カーネルトリックと言う手法を用いて計算量を抑えることができる。
ニューラルネットワーク
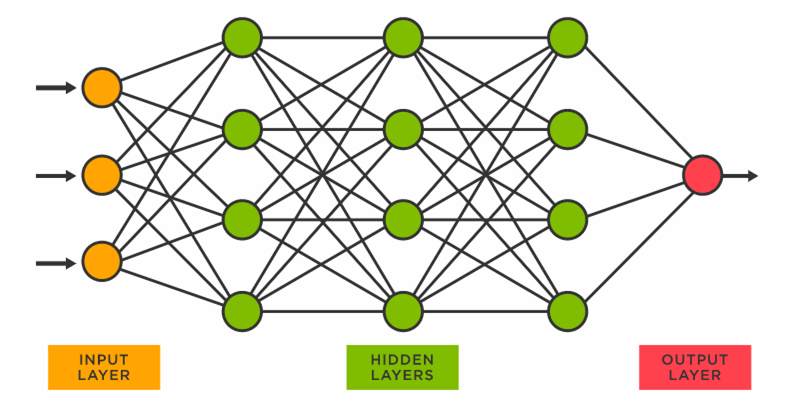
ニューラルネットワークとは人間の脳の中の構造を模したアルゴリズムのこという。入力を受け取る部分を入力層、出力する部分を出力層と表現する。入力層における各ニューロンと、出力層におけるニューロンの間のつながりは重みで表され、どれだけの値を伝えるかを調整する。そして、出力が0か1の値をとるようにすることで、正例と負例の分類を可能にする。ニューラルネットワークのモデルには、複数の特徴量(入力)を受け取り、1つの値を出力する単純パーセプトロン、入力層と出力層の間に隠れ層を追加することで非線形分類も行うことを可能とする多層パーセプトロンがある。
層が増えることによって調整すべき重みの数も増えるが、予測値と実際の値との誤差をネットワークにフィードバックするアルゴリズムである誤差逆伝播法(backpropagation)がある。
機械翻訳 機械翻訳(きかいほんやく、英: machine translation)とは、ある自然言語を別の自然言語に翻訳する変換を、コンピュータを利用して全て(ないし、可能な限り全て)自動的に行おうとするもの[…]
多層パーセプトロン
順伝播型ニューラルネットワークの一分類である。入力ノードを除けば、個々のノードは非線形活性化関数を使用するニューロンである。多層パーセプトロンにおけるハイパーパラメータは学習率である。
活性化関数
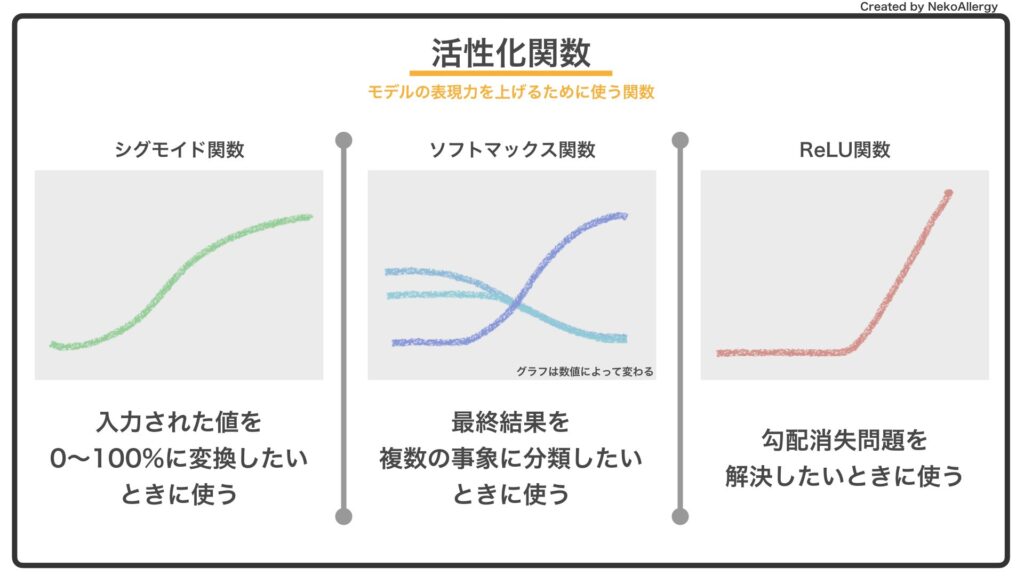
入力に対して出力を調整するための関数であり、予測の精度に影響がある。単純パーセプトロンでは活性化関数としてステップ関数を用いた場合に相当する。
初期は出力を正規化するためシグモイド関数がよく利用されていたが、勾配消失が起きにくいReLU関数が用いられている。出力層付近ではソフトマックス関数も使用される。
| シグモイド関数 | 任意の値を0から1に写像し、正例(+1)と負例(0)に分類するための関数。閾値を設定し、閾値を境に正例or負例に分類することができる。 |
| ソフトマックス関数 | 3種類以上の分類を行いたい場合に、シグモイド関数に代わって扱う活性化関数。各ユニットの総和を1に正規化することができる。主に分類問題の出力層で使われる。 |
本コンテンツは、日本ディープラーニング協会のG検定を想定したコンテンツとなっております。 探索・推論 探索木 場合分け。場合分けを続けていけば、いつか目的の条件に合致するという考え方。コンピュータの得意とする単純作業探[…]

自己回帰モデル(ARモデル)
一般に回帰問題に適用されるが、対象は時系列データである。時系列データ分析のことを単純に時系列分析(time series analysis)とも呼ぶ。入力が複数種類の場合、自己回帰モデルをベクトル自己回帰モデル(vector autoregressive mode、VARモデル)と呼ぶ。
相関係数
互いの特徴量の相関の正負と強さを表す指標のこと。1に近いほど強い正の相関、-1に近いほど負の相関を持つ。
多重共線性
相関係数が大きい場合に特徴量の組みを同時に説明変数に選ぶと予測がうまくいかなくなる現象のこと。相関係数をよく観察して特徴量を選択する。
疑似相関
2つの事象に直接の相関性(因果関係)がないのに、見えない要因(潜伏変数)の存在によってあたかも因果関係があるかのように推測される状態。 両者の単相関係数は見た目上、高い値となるため、「見かけの相関」と呼ばれることもある。
過去数年にわたって、ディープラーニングのようなハイテク概念の出現と、GAFAのようないくつかの巨大な組織によるビジネスへの採用がありました。ディープラーニングが世界的に注目されているのには、様々な要因があります。 この記事では、ディ[…]

単回帰分析と重回帰分析
線形回帰には1つの説明変数の1次関数で目的変数を予測する単回帰分析と、複数の説明変数の1次関数で目的変数を予測する重回帰分析がある。
単回帰分析
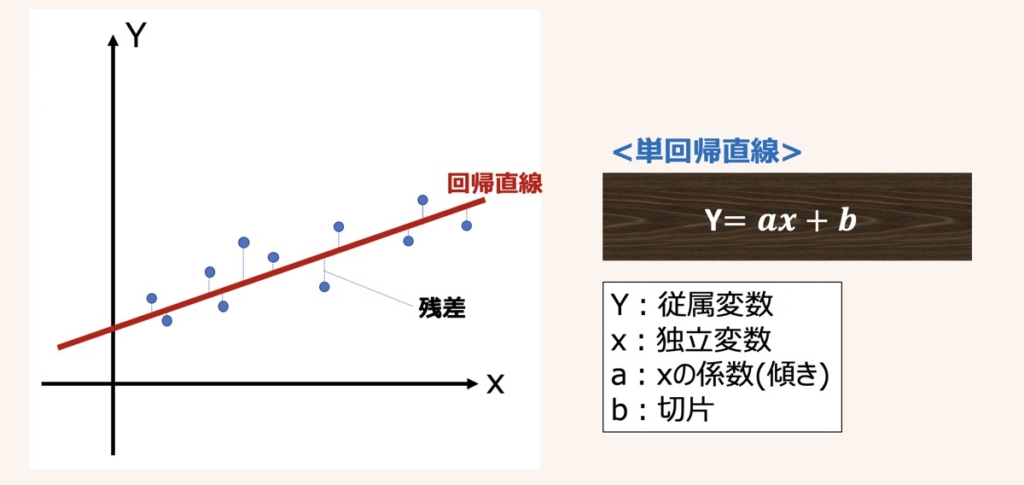
単回帰分析とは、単一の独立変数(説明変数)xに基づいて,連続値をとる従属変数(目的変数)Yを予測する分析手法です。説明変数が1つだけの単回帰モデルの方程式は上図のように示されます。
実測値に基づくサンプル(xn, yn)に適合するように引かれた直線を回帰直線と呼びます。
得られた回帰直線(方程式)をもとに未知の値Yを予測するには、既知の説明変数xを方程式に代入することで、予測値が得られます。
回帰直線から各サンプルへ伸びる縦線は残差(予測誤差)と呼ばれ、実測値と予測値の誤差を示しています。
重回帰分析
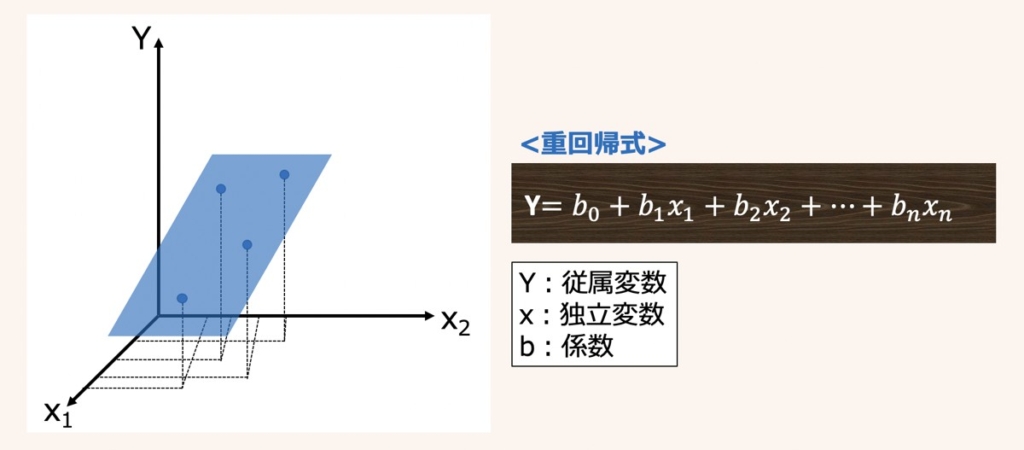
重回帰分析とは、複数の独立変数(説明変数)x1~xnに基づいて,連続値をとる従属変数(目的変数)Yを予測する分析手法です。
単回帰分析が、1つの目的変数を1つの説明変数で予測したのに対し、重回帰分析は1つの目的変数を複数の説明変数で予測しようというものです。多変量解析の目的のところで述べた、身長から体重を予測するのが単回帰分析で、身長と腹囲と胸囲から体重を予測するのが重回帰分析です。
上図に3次元の重回帰グラフの例(左図)とn次元の重回帰式(右図)をそれぞれ示します。
重回帰式のb0は目的変数Yの切片、b1〜bnは説明変数x1〜xnの係数を表しています。
ディープラーニングの出力層の違い
回帰
回帰(Regression)とは、簡単に言うと「連続的な数値の予測」です。
推定したい数値の範囲に応じて、活性化関数を選ぶ必要があります。
回帰では、二乗誤差を全サンプルで加算したものを誤差関数とします。
2クラス分類
出力が連続値ではなく、画像認識のケースだと「顔」か「顔以外」といったように入力を2つに分類するものが2クラス分類です。このとき、ラベルdが1のときに「顔」、0のときに「顔以外」といったように各クラスに2値の正解値を付与します。
多クラス分類
多クラス分類では、入力画像が「人の顔」なのか、「猫の顔」か、「犬の顔」か、「猿の顔」なのかといったように、入力データを複数のクラスに分類します。数字の0から9と書かれた画像を分類する(文字を読み取る)場合も、この多クラス分類となります。
全人類をデジタル管理 国際的な資本家(グローバリスト)がワクチンを推し進める理由はお金だけではありません。 今、国連は、SDGs(持続可能な開発目標)の「2030年までにすべての人に出生証明を含む法的なアイデン[…]

プルーニング
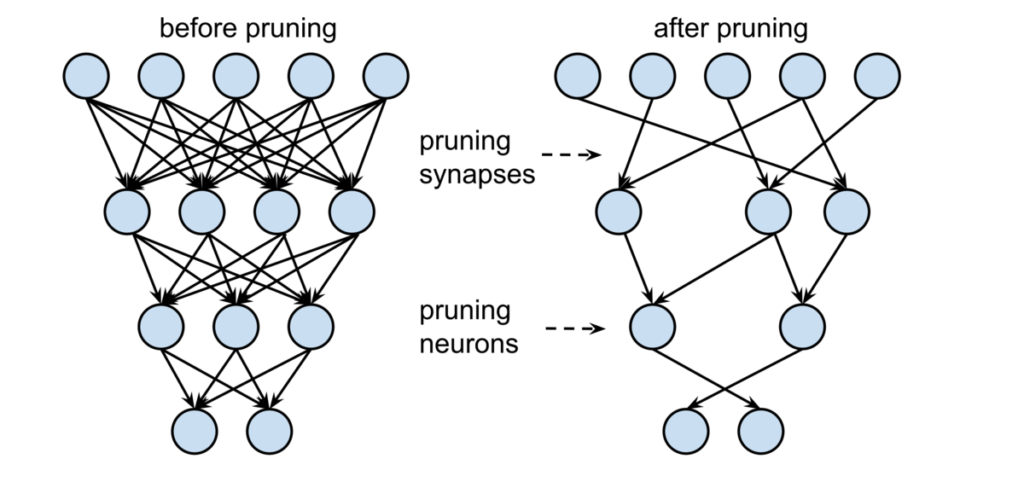
プルーニングは、マシン学習および検索アルゴリズムのデータ圧縮技術であり、インスタンスを分類するために重要ではなく冗長なツリーのセクションを削除することにより、決定ツリーのサイズを縮小します。剪定は、最終的な分類器の複雑さを軽減し、したがって、過剰適合を減らすことによって予測精度を向上させます。


世界的にワクチン接種を2回しても、感染を防ぐ効果が全くないことが露呈してしまいましたが、ワクチンを強要する社会、ワクチンパスポートがないと何もできない社会に誘導しようとしている事に強烈な違和感を感じます。 ワクチン接[…]