本コンテンツは、日本ディープラーニング協会のG検定を想定したコンテンツとなっております。
探索・推論
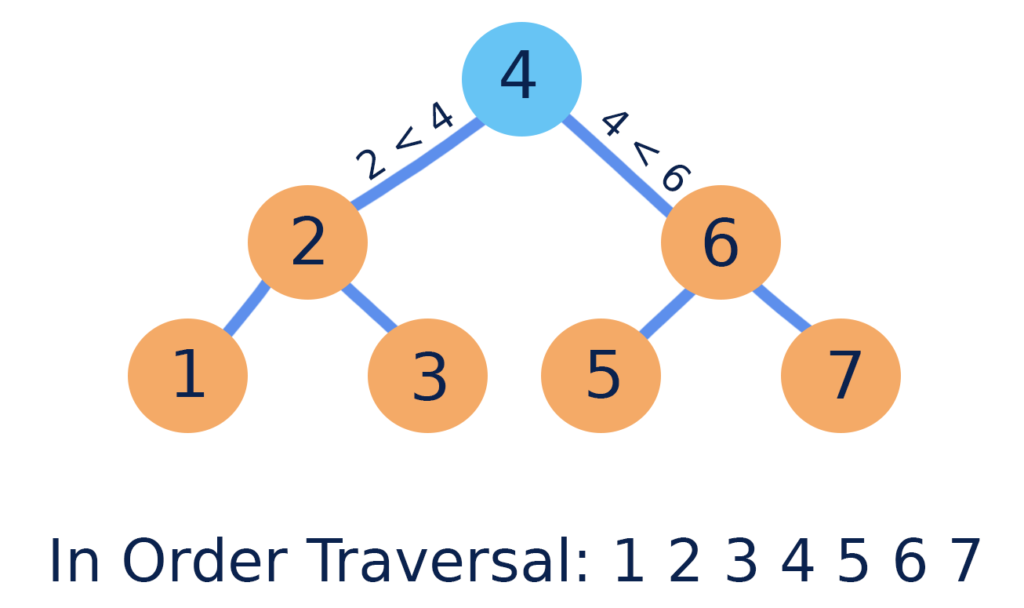
探索木
場合分け。場合分けを続けていけば、いつか目的の条件に合致するという考え方。コンピュータの得意とする単純作業
探索木とは、計算機科学において特定のキーを特定するために使用される木構造である。 その木構造が探索木として機能するために、あるノードのキーは、そのノードの左の子ノードのキーよりは常に大きく、逆に右の子ノードのキーよりは常に小さい性質が必要である。
幅優先探索
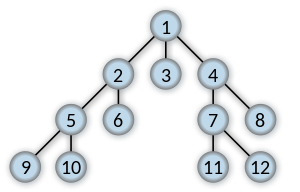
幅優先探索とは、グラフや木構造を探索するためのアルゴリズムの一つで、探索を開出発点に近いノード(探索木の各要素)順に検索。出発点から遠いノードほど検索は後になる。最短距離でゴールにたどり着く解を見つけることができる。しかし探索の途中で立ち寄ったノードをすべて記憶しておく必要があり複雑な場合メモリ不足で処理失敗の恐れがある。
深さ優先探索
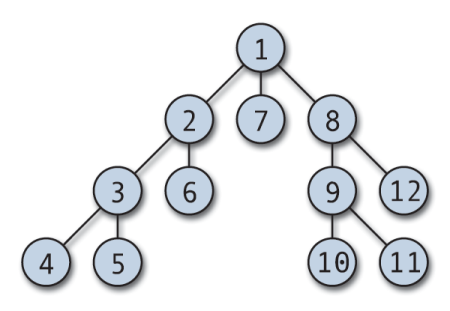
深さ優先探索とは、グラフや木構造を探索するためのアルゴリズムの一つで、それ以上先に進めない行き止まりのノードに出くわすまで経路を戻らずに隣接ノードを進んでいく方式。あるノードから行けるところまで行って、行き止まりになったら1つ手前のノードに戻って探索を行うということを繰り返す。1つ手前のノードに戻って探索するためメモリはあまり要らない。しかしそれが最短距離でゴールにたどり着く解であるとは限らない。
プランニング(探索空間)
プランニングとは、シミュレーションなどを通して現状を認識し、問題点を分析した後、目的を達成するための行動順序などを具体化をすること。
自動計画とも呼ばれていて、例としては、知的エージェント、自律型ロボット、無人航空機などが挙げられる。分類問題などとは違って自動計画の解は複雑で未知であるので、多次元空間での発見と最適化が必要とされる。よく練られた計画はロードマップと呼ばれ、また、計画の修正のことを特にリプランニングと呼ぶ。プランニングには、動的計画法、強化学習、組合せ最適化などが含まれる。
STRIPS
STRIPS(Stanford Research Institute Problem Solver)とは、1971年、リチャード・ファイクスとニルス・ニルソンが開発した(前提条件、行動、結果)の3つを組み合わせて記述するプランニング(行動計画)システム
SHRDLU
SHRDLUとは、積み木の世界に英語で指示を与えることで物体を動かすことができるプランニング(行動計画)システム。1968年から1970年にかけて、テリー・ウィノグラードによって開発された。英語による指示を受け付け、コンピュータ画面に描かれる「積み木の世界」に存在する様々な物体(ブロック、四角錐、立方体など)を動かすことができた。
アルファ碁

《AlphaGo》米国グーグルディープマインド社が開発した、囲碁対局用の人工知能。 ディープラーニングにより、過去の膨大な棋譜を学び、さらに、自身作成のプログラムと多数対戦することで強化学習を行っている。
問題点は組み合わせの数が天文学的な数字になってしまうため、事実上すべてを探索しきれないこと。

ヒューリスティック
ヒューリスティクスとは「経験則の」「試行錯誤的な」という意味で、計算機科学において、答えの精度はそう高くない(必ずしも正解を導き出せるわけではない)が、ある程度正答に近い答えを出せる方法のこと。IT業界では主にコンピューターにシミュレーションや計算をさせる時用いられる。
例えば「決まったアルゴリズムなら確実な結果を出せるが、正しい解にたどり着くためには膨大な手順や計算が必要だ」という時や、新種のウイルス発見をはじめとして既存のデータを参考にできない目的がある時には、このヒューリスティクスという手法が最適である。
ミニマックス法
ミニマックス法(minimax)またはミニマックス探索とは、想定される最大の損害が最小になるように決断を行う戦略のこと。将棋、チェス、リバーシなどといった完全情報ゲームをコンピュータに思考させるためのアルゴリズムとしても用いられるが、元々はフォン・ノイマンが中心となって数学的に理論化されたゲーム理論において、打ち手を決定する際に適用されるルールの一つ。これに対し、想定される最小の利益が最大になるように決断を行う戦略はマクシミン戦略という。
アルファ・ベータ法

アルファ・ベータ法(alpha-beta pruning)は完全情報ゲームにおける探索アルゴリズムの1つである。基本的にミニマックス法と同じであり、同じ計算結果が得られるが、ゲーム木において、計算しなくても同じ計算結果になる部分を枝刈りしている。
ブルートフォース攻撃
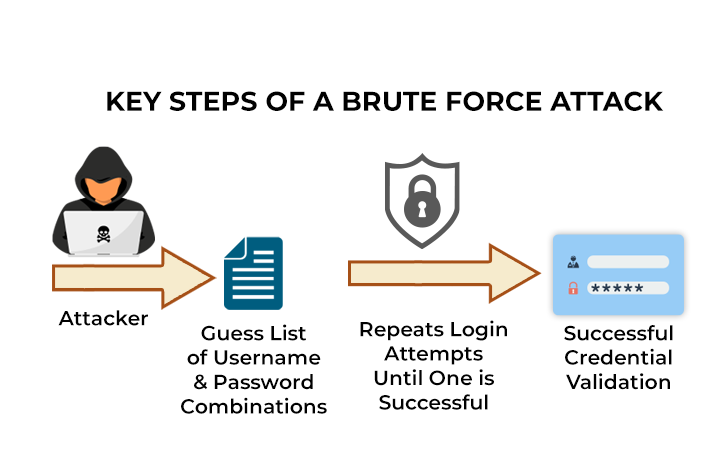
ブルートフォース攻撃とは、日本語では「総当たり攻撃」と訳される、暗号解読や認証情報取得の手法です。主にパスワードを不正に入手するために用いられます。
ハノイの塔

ハノイの塔(Tower of Hanoi)は、パズルの一種。 バラモンの塔または ルーカスタワー(Lucas’ Tower)とも呼ばれる。
探索木を使ってハノイの塔というパズルを解くことができる。
コスト
ヒューリスティックな知識:効率よく探索するためにコストの概念。「探索を効率化するのに有効な」という意味で、探索に利用する経験的な知識である。
コンピュータが効率よく最良の手を探索できるように、状態が自分にとって有利か不利かを示すスコア(コスト)を情報として保持。ゲーム盤の状態のスコア(コスト)の計算方法を事前に決めておけばよく、駒の数や位置関係を元に計算する。
モンテカルロ法
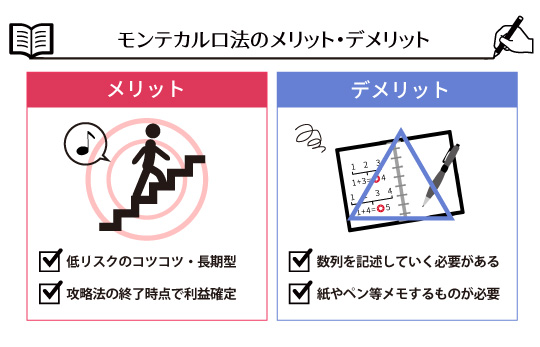
モンテカルロ法(Monte Carlo method、MC)とはシミュレーションや数値計算を乱数を用いて行う手法の総称。元々は、中性子が物質中を動き回る様子を探るためにスタニスワフ・ウラムが考案しジョン・フォン・ノイマンにより命名された手法。カジノにて多用され、カジノで有名な国家モナコ公国の4つの地区(カルティ)の1つであるモンテカルロから名付けられた。ランダム法とも呼ばれる。

ロボットの知能が実現する行動

ロボットにおける知能として、 ロボットに知的な動作をさせるためにどのような機能が必要か、 生物の知能や人工知能と比較してロボットに特有の知能とは何かについて考えてみる。 この後の章で順次取り上げるが、ロボットの知能が実現する行動として、 低次の働きから順に 反応行動 、 計画行動 、 適応行動 、 協調行動 に分類できることを示す。
反応行動
反応行動 とは、自分(ロボット)の周囲のごく狭い範囲の環境から入力される外部の情報 (様々なセンサからの情報)に対して引き起こされる単純な行動である。 その行動は一定で変化することはない。 このレベルでは、自分と自分の周囲のごく狭い範囲の環境(からの入力)しか存在しない。 反応行動では、 走性、反射、感覚運動写像、行動単位の重ね合わせ、人工ポテンシャル法、運動の スキーマ、行動の分解およびモジュール化、有限オートマトンによるモデル化 などの概念が関係する。
計画行動
計画行動 とはロボットを取り巻く環境内で自分(ロボット)の位置、 および達成目標に関係する物体の位置を把握して、 目標達成のために計画する移動や運動を表す。 このレベルでは、自分と自分の周囲の広い範囲の環境(からの入力)が存在する。 環境は静的で変化しない。 計画行動では、 空間記憶と認知地図、座標系について学ぶ。 次に応用として、 自己位置同定とそれを実現する手法、空間表現、コンフィグレーション空間、 状態空間モデル などの概念が関係する。ロボットの計画行動は探索で作成可能。
適応行動
適応行動 とは環境や外部からの入力(センサ情報)が変化する場合に、 それぞれの環境や入力に対して自分の行動を変化させ、 望ましい行動を実現することである。 このレベルでは、自分と自分の周囲の環境(からの入力)が存在する。 環境は動的で変化する。 適応行動を実現するには環境の変化に対応して自分の行動を変化させる 何らかの学習の仕組みが必要となる。 その手法として、強化学習、人工神経回路網、ニューラルネットワーク などが広く利用されている。
協調行動
協調行動 とは複数台のロボットが協調、協力して全体の目標を達成するような 行動を表す。単独の個体で取り組むよりも複数の個体が協調、 または役割分担を決めて取り組んだ方が目標を達成しやすい場合に協調行動が必要となる。 このレベルでは、自分と自分の周囲の環境(からの入力)、自分以外の個体が存在する。 協調行動に関係する概念として、コミュニケーション、観察による協調、群れ行動、 サブゴールの生成、マルチエージェント、共進化 などがある。