データの増加と機械学習
機械学習:人工知能のプログラム自身が学習する仕組み。
コンピュータは与えられたサンプルデータを通してデータに潜むパターンを学習。
ユーザーの好みを推測するレコメンデーションエンジンや迷惑メールを検出するスパムフィルターなども、膨大なサンプルデータを利用できるようになった機械学習によって実用化されたアプリケーション。
レコメンドエンジン

レコメンドエンジンとは、サイトへの訪問者が購入したり見たりした商品と関連性があり、購買意欲をかきたてるような商品を提案することで、顧客が欲しいと思う情報を探すのを手助けしてくれるシステムです。 昨今ECサイトだけでもかなりの数があり、加えて様々な口コミサイトや広告も含めた商品に関する情報が溢れています。
スパムフィルター
受信したメールを解析し、スパムメール(迷惑メール)であるかどうかを判定する仕組み。 送信したメールがスパム判定された場合、受け取り手の受信ボックスにメールが届かなくなる。
自然言語処理
自然言語処理(natural language processing、略称:NLP)は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言語学の一分野である。「計算言語学」(computational linguistics)との類似もあるが、自然言語処理は工学的な視点からの言語処理をさすのに対して、計算言語学は言語学的視点を重視する手法をさす事が多い。データベース内の情報を自然言語に変換したり、自然言語の文章をより形式的な(コンピュータが理解しやすい)表現に変換するといった処理が含まれる。応用例としては予測変換、IMEなどの文字変換が挙げられる。
自然言語の理解をコンピュータにさせることは、自然言語理解とされている。自然言語理解と、自然言語処理の差は、意味を扱うか、扱わないかという説もあったが、最近は数理的な言語解析手法(統計や確率など)が広められた為、パーサ(統語解析器)などが一段と精度や速度が上がり、その意味合いは違ってきている。もともと自然言語の意味論的側面を全く無視して達成できることは非常に限られている。このため、自然言語処理には形態素解析と構文解析、文脈解析、意味解析などをSyntaxなど表層的な観点から解析をする学問であるが、自然言語理解は、意味をどのように理解するかという個々人の理解と推論部分が主な研究の課題になってきており、両者の境界は意思や意図が含まれるかどうかになってきている。
・形態素解析
・構文解析
・語義の曖昧性解消
・照応解析
本コンテンツは、日本ディープラーニング協会のG検定を想定したコンテンツとなっております。 人工知能の定義 人工知能とは何か 「人工知能(Artificial Intelligence)」:1956年にアメリカで開催され[…]

コーパス
コーパスは、言語学において、自然言語処理の研究に用いるため、自然言語の文章を構造化し大規模に集積した言語テキストの集合体を指す。構造化し、言語的な情報を付与している。言語学以外では「全集」を意味することもあり、言語学でも日本語を扱う場合には、「言語全集」「名詞全集」「動詞全集」などと呼ばれている。ラテン語で「身体」を意味する ‘corpus’ が由来。 近年では電子化されデータ利用できるものがほとんどで、「電子コーパス」と同義でとらえられる。
パーセプトロン
パーセプトロンは、人間の脳神経回路を真似た学習モデルです。人口ニューロンとも呼ばれ、神経組織ニューロンをモデル化した、形式ニューロンを数式化したものである。
パーセプトロンの仕組みはシンプルで、複数の入力を重み付けして、0か1を出力するだけのものです。
バイアス +(入力1 × 重み1)+(入力2 × 重み2)= a
a ≦ 0 なら 0 を出力
a > 0 なら 1 を出力
誤差逆伝播法
バックプロパゲーション(英: Backpropagation)または誤差逆伝播法(ごさぎゃくでんぱほう)はニューラルネットワークの学習アルゴリズムである。
バックプロパゲーションは数理モデルであるニューラルネットワークの重みを層の数に関わらず更新できる(学習できる)アルゴリズムである。ディープラーニングの主な学習手法として利用される。
そのアルゴリズムは次の通りである。
- ニューラルネットワークに学習のためのサンプルを与える。
- ネットワークの出力を求め、出力層における誤差を求める。その誤差を用い、各出力ニューロンについて誤差を計算する。
- 個々のニューロンの期待される出力値と倍率 (scaling factor)、要求された出力と実際の出力の差を計算する。これを局所誤差と言う。
- 各ニューロンの重みを局所誤差が小さくなるよう調整する。
- より大きな重みで接続された前段のニューロンに対して、局所誤差の責任があると判定する。
- そのように判定された前段のニューロンのさらに前段のニューロン群について同様の処理を行う。
- アルゴリズム名が示唆するように、エラー(および学習)は出力ノードから後方のノードへと伝播する。
技術的に言えば、バックプロパゲーションはネットワーク上の変更可能な重みについて、誤差の傾斜を計算するものである。この傾斜はほとんどの場合、誤差を最小にする単純なアルゴリズムである確率的最急降下法で使われる。「バックプロパゲーション」という用語はより一般的な意味でも使われ、傾斜を求める手順と確率的最急降下法も含めた全体を示す。バックプロパゲーションは通常すばやく収束して、対象ネットワークの誤差の局所解(区間を限定したときの極小値、極値参照)を探し出す。人工ニューロン(または「ノード」)で使われる活性化関数は可微分でなければならない。また、ガウス・ニュートン法とも密接に関連する。
オートエンコーダ
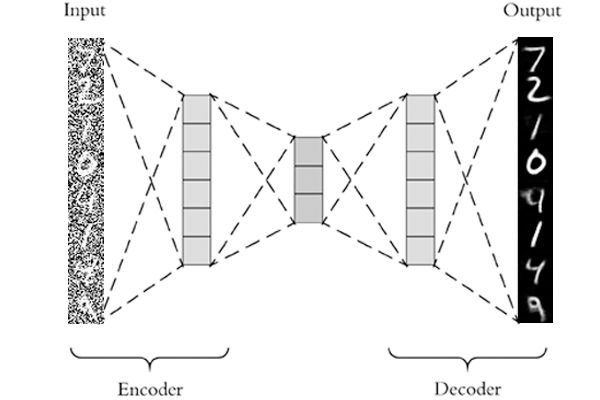
オートエンコーダとは、データの次元を削減し、圧縮する手法です。 ニューラルネットワークが機能するための仕組みの1つとして、勾配消失や過学習を防ぐ目的で提唱されました。 今ではそれらの目的で使われることはあまりありません。 しかし、画像ノイズ除去や異常検知システムの仕組みとして活用されています。

過去数年にわたって、ディープラーニングのようなハイテク概念の出現と、GAFAのようないくつかの巨大な組織によるビジネスへの採用がありました。ディープラーニングが世界的に注目されているのには、様々な要因があります。 この記事では、ディ[…]

ILSVRC
ILSVRCは、ImageNet Large Scale Visual Recognition Challengeの略である。 大規模な画像データセットImageNetを保有する組織が提唱し、2010年から始まった。 スタンフォード大学やプリンストン大学などが運営にかかわる。
画像に写っているものが何なのかをコンピュータが推測する課題が与えられ、正解率を競い合う。コンピュータは1000万枚の画像データを使って学習し、その学習成果をテストするために用意された15万枚の画像を使って正解率を測定します。
2012年、画像認識の精度を競い合う競技会ILSVRC(ImageNet Large Scale Visual Recognition Challenge)でトロント大学のジェフリー・ヒントンが率いるSuperVisionが勝利しました。
ジェフリー・ヒントンが中心となって開発した新しい機械学習の方法が「深層学習(ディープラーニング)」(開発されたニューラルネットワークのモデルはAlexNet)。
チャンピオンのエラー率: 2010年で28%、2011年で26%、2012年は15.3%で優勝。
2012年以降、ILSVRCのチャンピオンはすべてディープラーニングを利用。2015年に人間の画像認識エラーである4%を抜いた。エラー率は劇的に改善している。
特徴量
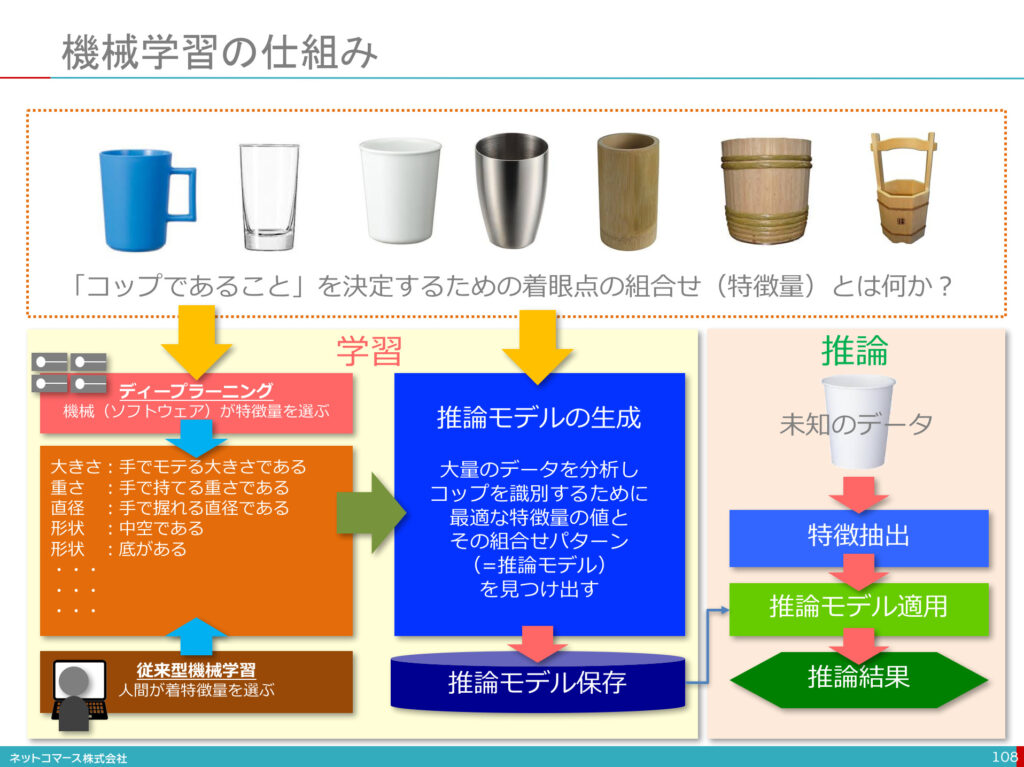
分析すべきデータや対象物の特徴・特性を、定量的に表した数値。 ディープラーニングなどの機械学習による予測や判断の精度を高めるためには、必要な特徴量のみを適切に選択することが重要となる。
次元の呪い
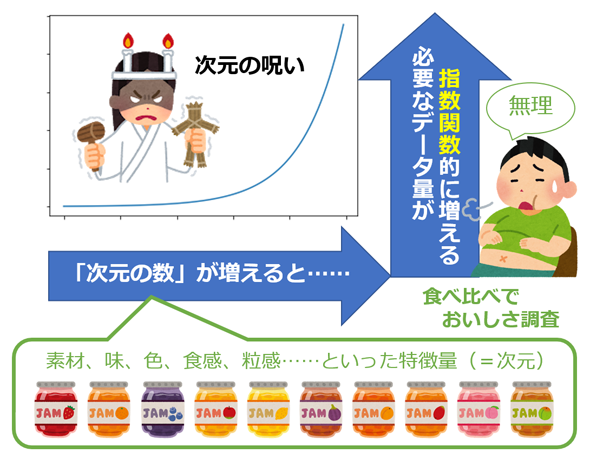
「次元の呪い」とは、データの次元(要素数)が大きくなると、そのデータを分析する際の計算量が指数関数的に増大する現象を指す。 次元の呪いを回避するため、一般的に機械学習の高次元データは次元を減らす。

人工無脳(知識なしでも知性があるように感じる人間心理の不思議) 人工無脳:チャットボット、おしゃべりボットなどと呼ばれているコンピュータプログラム。特定のルール・手順に沿って会話を機械的に処理するだけで、実際は会話の内容を理解して[…]

機械学習
機械学習(machine learning)とは、経験からの学習により自動で改善するコンピューターアルゴリズムもしくはその研究領域で、人工知能の一種であるとみなされている。「訓練データ」もしくは「学習データ」と呼ばれるデータを使って学習し、学習結果を使って何らかのタスクをこなす。例えば過去のスパムメールを訓練データとして用いて学習し、スパムフィルタリングというタスクをこなす、といった事が可能となる。
機械学習は以下の分野と密接に関係する
- 計算統計学(英語版):計算機を使った予測に焦点を当てた分野
- 数理最適化:定められた条件下における最適解の探索に焦点を当てた分野
- データマイニング:教師なし学習(後述)における探索的データ解析に焦点を当てた分野
機械学習という名前は1959年にアーサー・サミュエルによって造語された。
パターン認識
パターン認識とは、画像や音声など膨大なデータから一定の特徴や規則性のパターンを識別して取り出す処理のこと。 人間が行っている知的行動をコンピュータに実現させるための自然情報処理のひとつである。 パターン認識の中で使われる頻度が高いものが「顔認識」「音声認識」「文字認識」である。
画像認識
画像認識 (Image Recognition)とは、画像および動画から文字や顔などのオブジェクトや特徴を認識し検出するパターン認識技術の一分野です。 背景から特徴を分離抽出しマッチングや変換をおこない、目的となるオブジェクトや特徴を特定し認識します。
特徴抽出
特徴抽出は、画像の関心部分をコンパクトな特徴ベクトルとして効率的に表現する、一種の次元削減です。 この手法は、画像のサイズが大きく、画像のマッチングや検索などのタスクを素早く実行するために簡潔な特徴表現が必要なときに便利です。
機械学習、パターン認識、画像処理では、特徴抽出は測定データの初期セットから始まり、有益で非冗長であることを目的とした派生値を構築し、その後の学習と一般化のステップを容易にします。
OCR
光学文字認識は、活字、手書きテキストの画像を文字コードの列に変換するソフトウェアである。画像はイメージスキャナーや写真で取り込まれた文書、風景写真、画像内の字幕が使われる。一般にOCRと略記される。
機械学習と統計的自然言語処理
統計的自然言語処理を使った翻訳では、従来のように文法構造や意味構造を分析して単語単位で訳を割り当てるのではなく、複数の単語をひとまとまりにした単位(句または文単位)で用意された膨大な量の対訳データをもとに、最も正解である確率が高い訳を選択する。
ニューラルネットワーク
ニューラルネットワークは機械学習のベースとなり、人間の神経回路を真似することで学習を実現する。
ニューラルネットワークの元祖:米国の心理学者フランク・ローゼンブラットが1958年に提案した単純パーセプトロンというニューラルネットワーク
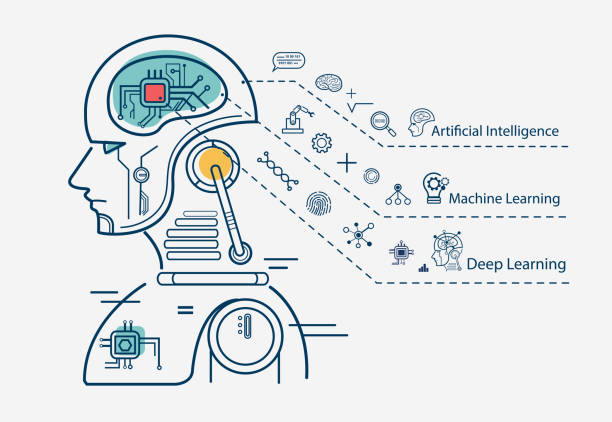
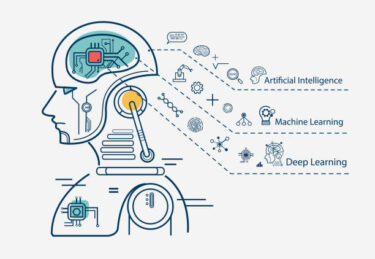
ディープラーニング(深層学習)
ニューラルネットワークを多層にしたものがディープラーニング(深層学習)
パーセプトロンの限界:多層化することでディープラーニングは簡単に実現できる
→人工知能のマービン・ミンスキー:特定の条件下の単純パーセプトロンでは、直線で分離できるような単純な問題しか解けないと指摘。
→ニューラルネットワークを多層にして、誤差逆伝播法(バックプロパゲーション)を用いて学習すれば克服
→ただし、多層にしても学習精度が上がらないという問題も:入力したものと同じものを出力するように学習する自己符号化器(オートエンコーダ)の研究や、層の間でどのように情報を伝達するかを調整する活性化関数の工夫などを足場にして、4層、5層と層を深くしても学習することが可能になる。
全人類をデジタル管理 国際的な資本家(グローバリスト)がワクチンを推し進める理由はお金だけではありません。 今、国連は、SDGs(持続可能な開発目標)の「2030年までにすべての人に出生証明を含む法的なアイデン[…]